Ordinary fixed-focus cameras, such as low-end hand-held cameras, smartphone cameras, and surveillance cameras, have a depth-variant point spread function (PSF) that can be visualized as double cones when focusing at finite distances or as a single cone when focusing at infinity with apex at the on-axis in-focus point located at the hyperfocal distance. Objects become progressively more defocused as their distance to the lens gets smaller than half of the hyperfocal distance. The prior knowledge of the volumetric PSF can be utilized effectively to deblur the captured image at different depth planes.
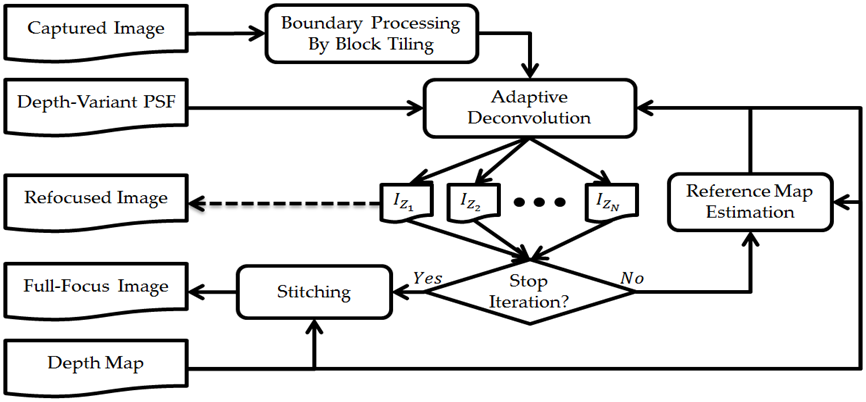
Figure 1: Block diagram of the computational depth-based deconvolution technique.
A computational depth-based deconvolution technique, presented in Fig. 1, has been developed to equip ordinary cameras with an extended depth of field capability. This is achieved by deconvolving the captured scene with pre-calibrated depth-variant point spread function profiles to bring it into focus at different depth planes. Afterward, the focused features from the depth planes are stitched together to form a full-focus image.

Figure 2: Stitching planar regions according to a depth map (left) to form MD objects for USAF (center) and cameraman (right).
To imitate multi-depth (MD) objects, different regions of planar objects traced at various depth planes are stitched together according to a customized depth map, presented in Fig. 2.
The ringing artifacts associated with the deconvolution process are addressed on three levels. First, the boundary artifacts are eliminated by adopting a block-tiling approach. Second, the sharp edges' ringing artifacts are adaptively controlled by reference maps working as local regularizers through an iterative deconvolution process. Finally, artifacts initiated by different depth surfaces are suppressed by a block-wise deconvolution or depth-based masking approach. The developed algorithm is demonstrated for planar objects and multi-depth objects scenarios.
 Figure 3: Visual comparison of final full-focus deconvolution results after stitching based on a depth map for USAF and cameraman images showing reference MD objects (first column), deblurring results of MD object without any depth processing (middle column), and deblurring results of MD object with depth-based masking approach (last column).
Figure 3: Visual comparison of final full-focus deconvolution results after stitching based on a depth map for USAF and cameraman images showing reference MD objects (first column), deblurring results of MD object without any depth processing (middle column), and deblurring results of MD object with depth-based masking approach (last column).
Note that the depth-transition artifacts can dominate the MD deconvolution results if no special processing is involved (see second column of Fig. 3). The depth-based masking approach can help a lot in reducing such artifacts (see last column in Fig. 3), although it is not fully restoring some of the image details (e.g., compare the vertical bars on the right of restored USAF images between the depth-based masking case and reference MD case).
This work was a collaborative effort with Prof. Rongguang Liang in the
College of Optical Sciences, University of Arizona.
Publications:
-
Basel Salahieh, Jeffrey J. Rodriguez, and Rongguang Liang, "A Computational Depth-Variant Deconvolution Technique for Full-Focus Imaging," Imaging and Applied Optics 2015, OSA Technical Digest, Optical Society of America (OSA), 2015, paper CT3F.5, 3pgs. Presented at Computational Optical Sensisng and Imaging (COSI), Arlington, VA, June 7-11, 2015. [ PDF ]
